


WAIC 2022 精彩回顾|澜舟科技分享大模型技术发展与应用实践
2022-09-05
2022年9月1日至3日,世界人工智能大会(WAIC)在上海召开,澜舟科技受邀参加了“大规模预训练模型主题论坛”和“AI开发者论坛”,我司创始人兼CEO周明和首席产品官李京梅出席并分享了关于大模型发展趋势和应用实践的见解。
大规模预训练模型主题论坛#
9月2日,在世界人工智能大会组委会的指导下,2022世界人工智能大会——大规模预训练模型主题论坛在上海世博中心召开,本次论坛由阿里巴巴集团主办,汇聚了阿里巴巴达摩院,阿里云,清华大学,复旦大学,澜舟科技,深势科技,IDEA研究院等机构,来自产学研届的大模型领域专家齐聚一堂,围绕大模型的创新,落地和开源开放展开了探讨。

澜舟科技创始人兼CEO周明博士作为主旨演讲嘉宾分享了《孟子预训练模型的产业化》。周明博士演讲开始表示,“恭喜阿里巴巴发布了通义大模型,看到这个大模型我也非常激动,这代表了整个中国在大模型领域的一个深刻思考,而且我也感念阿里巴巴的胸怀,有很多大模型核心的技术它也可以对外开放,再次祝贺靖人。”
周明博士接下来全面介绍了澜舟科技所从事的孟子轻量化模型在产业落地化的实践和思考。近三年来,继感知智能之后,认知智能崛起。大规模预训练模型深入应用于金融等行业场景中,大幅度地提升了业务系统的开发效率。此次演讲详细分享了目前大模型技术在金融等行业场景下的应用现状及未来发展趋势, 并且从工业界观点来看,如何实现认知智能的的落地, 必将涵盖从模型训练、模型快速适配、以及柔性AI智能云服务、开源等方式提供一系列的普惠服务。
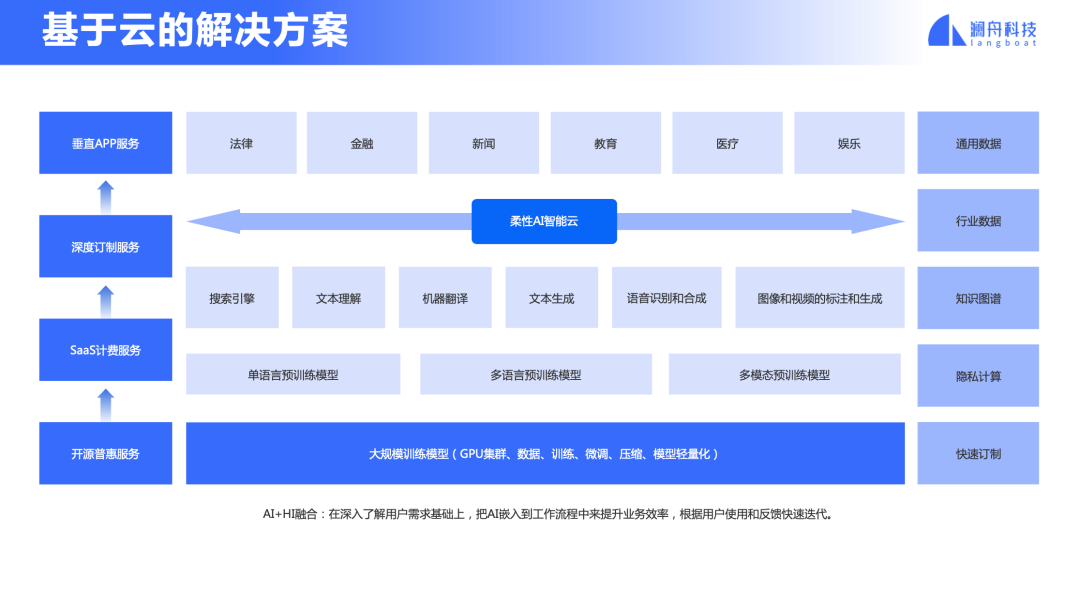
大模型推理的时候如何加快,甚至加快一些专用硬件的能力,提升它的速度,还有多模态产生某种意义上AGI的大模型研究。有了这些大模型怎么落地?周明博士总结了以下几种方式:
1、模型训练。首先需要积累各类互联网数据、双语数据、行业数据,然后通过实体、关系和时间抽取建立知识图谱。与此同时,建立大规模的预训练模型支持单语、多语、多模态的任务。在此基础上,支持各种自然语言的技术,包括搜索、文本理解、生成、翻译、语音、图像、视频等应用。这是所谓的能力层,用户用的时候确实不好用,因为它封装完大的模型体系下,你说我有各种各样的能力,但是用户有“最后一公里”的问题,用户如何很容易方便地用到你的模型,解决它的实际问题,这里用一个词概括叫“柔性AI智能云”。
2、模型快速适配,针对行业需要快速训练所需的模型。鉴于大模型在落地的时候部署代价大,需要考虑模型压缩和轻量化。为了解决NLP开发碎片化问题。我们希望建立一套基于预训练和微调机制的技术平台支撑所有语言、所有领域和任务的研发和维护。
3、柔性AI智能云服务。我们需要开发柔性AI智能云技术,使得用户可以傻瓜型的方式,以拖拉拽的功能,所见即所得地实现自己的功能,并且提供随着用户调用量灵活调度云服务器的弹性服务。
4、可以通过开源方式提供普惠服务,并建立一定的品牌。然后可通过SaaS提供付费服务,也可通过深度定制对重要客户提供服务。
为此,澜舟科技建立了面向金融行业的NLP技术与产品服务体系,分三大部分:澜舟的孟子预训练模型技术,澜舟基础NLP能力,以及金融NLP的应用场景。-
第一部分,具备多种架构,比如BERT、GPT、T5等架构的预训练模型的能力。
-
第二部分,NLP的基础能力,文本生成、实体识别、信息抽取。
-
第三部分,各种应用场景,像舆情分析、公告信息抽取、研报观点汇总、企业信用评估、ESG分析、IPO招股书审核、量化因子、智能文档审计等等。
目前基础NLP能力和可标准化的金融的NLP能力已经在澜舟官网上公开测试了。另外,澜舟也在开发金融零样本NLP平台,开放模型定制能力,应用零样本、少样本学习技术,降低NLP定制门槛,满足碎片化应用场景。未来几个月内将会发布出来。
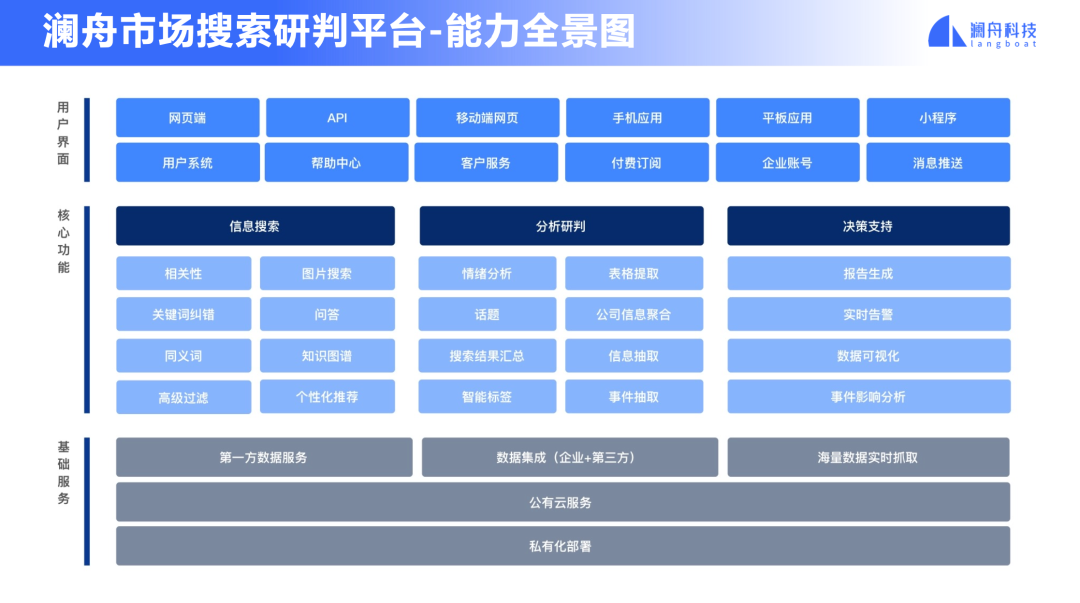
我们跟金融企业密切合作,深入企业原有生态,方便接入RPA和无代码编程体系,实现低门槛、易上手、更快触达金融业务场景。我们也提供私有化定制部署,深入企业业务场景,最大化利用企业私域数据,从预训练到微调任务全面优化性能,用我们孟子轻量化技术为企业实现高性能价格比的训练和部署。我们也开发了市场搜索和研判平台。为市场研究和投资决策提供信息搜索和分析研判。在新闻、公告、研报、政策等频道,针对公司的基本信息、事件、行业、概念进行搜索,并在搜索结果上显示话题、情绪分析等研判信息。
金融机器翻译方面, 澜舟利用了大规模的语料进行多语言的翻译,我们针对金融特点收集了大规模的金融数据,也是单/双语,得到了一个金融的翻译模型。

澜舟市场搜索研判平台,我们想帮助投资市场研究人员在新闻、公报、年报,针对公司的基本信息、事件、行业信息进行智能搜索,进一步提供增值服务。
未来人工智能将进一步深入到企业业务流程,人们会更多地看到人工智能创造的价值,而不止是人工智能本身。AI与场景无缝结合,AI与HI融为一体才是王道。

论坛最后圆桌环节,澜舟科技首席产品官李京梅主持并参加了《大模型的创新、应用和生态建设》讨论,其他参与讨论的嘉宾分别为来自阿里云智能的研究员林伟,复旦大学计算机学院教授邱锡鹏,IDEA研究院讲席科学家张家兴,达摩院资深算法专家及AliceMind负责人黄松芳、M6-OFA负责人周畅、资深视觉算法专家赵德丽。 嘉宾们就大模型的定义,什么是好的大模型的标准,以及大模型的范式、落地、生态建设及未来展望做了深入讨论,通用大模型和专业小模型在一定时间内还是会并存或者彼此依赖,在特定领域、特定场景下需要基于大模型做finetune微调才做到SOTA,落地实现业务价值。更多开放的海量数据,更多用得起的云化的算力,和更多可获取的开源大模型也是众望所至。

最后李京梅总结道,“今天大模型在工业界落地的时候我们看到了很多场景,技术上也确实有了很大的突破,但是如果说真的能够为企业创造价值以及广泛的规模化, 我觉得还是有一段距离。人工智能的未来,尤其大模型的未来我们在此共同做一个呼吁,产学研、中小企业、大平台可以多方共同合作,争取在不久的将来可以看到更多大模型的落地,为业务创造得更多价值!”
AI开发者论坛#
9月3日,在机器之心承办的 WAIC 2022 · AI开发者论坛上,以2021图灵奖得主为代表的全球最具影响力学术领袖、技术专家和企业高管发表主题演讲,演讲内容包括高性能计算、多模态交互、文本生成研究与应用、RPA、类脑计算等在内的最前沿议题。本次大会以「 AI 开发者所真正关注的」为主题,集中展示本年度人工智能领域最前沿技术成果和最新实践应用进展。

澜舟科技创始人兼CEO周明博士作为主讲嘉宾出席并分享了《基于预训练语言模型的可控文本生成研究与应用》,主要从四个部分进行介绍:可控文本生成背景、可控文本生成研究进展、澜舟可控文本生成应用实践、总结与展望。

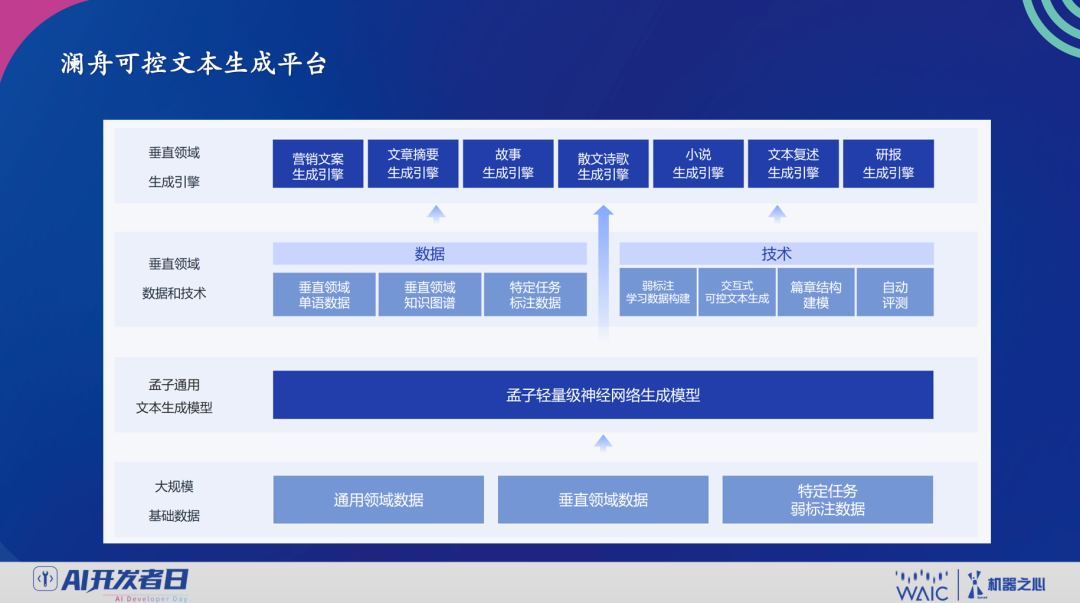
说到可控文本生成研究进展,周明博士总结了三个技术要点:可控文本生成神经网络模型、可控文本生成模型训练与解码、改进生成文本的事实正确性。此外,周明博士还分享了澜舟科技在可控文本生成上的应用实践。澜舟基于孟子预训练语言模型,开发了一系列的文本生成应用,为了更好地实习落地,采用了轻量化技术。最底层是通用预训练模型,基于大规模基础数据训练孟子通用文本生成模型,然后基于垂直领域的数据,在上层开发各个垂直领域的应用,如营销文案生成、小说生成等。
最后,周明博士总结:“基于预训练语言模型的文本生成技术水平日益提高,已经开始从研究逐渐走向落地,在各行各业中得到广泛应用,如营销领域、文学辅助写作领域、研报写作领域等。未来需要重点关注的研究方向包括长文本生成的神经网络模型、篇章一致性、事实正确性、自动评测等。面向工业落地,我们还需研究轻量化模型、快速领域适配算法、小样本学习等技术,降低落地成本。”




