







解决方案简介
智能投研解决方案
聚焦投研信息搜写一体化呈现,形成“知识库自动扩充-碎片信息自动整合-报告文档自动撰写”的智能化闭环,提升投研信息获取和分析的效率与质量。
业务场景和痛点
痛点
01

知识深度不足
传统投研数据库已完成研报、纪要、资讯、公告等非结构化数据的收集和整理,但缺乏基于这些数据形成投研领域专业深度的知识整理和分析。
痛点
02

检索精度不够
每日大量公告、研报的更新,基于关键词匹配的传统检索,难以把握用户真实意图,不能有效借鉴外部数据,无法精确掌握投研趋势。
痛点
03

报告耗时较长
案头文件格式多样,参考内容繁多且复杂,需要花费较长时间整理呈现,无法自动生成周月报、点评、投研报告等,导致投研信息反馈不够及时。
痛点
04

问答体验不好
传统投研问答交互过程中,无法准确理解用户问题,对投研领域知识深度的问题无法补全、改写等,导致交互效率低,用户体验差。
智能投研解决方案
基于语义理解和投研领域的知识扩充
基于孟子预训练模型技术体系,通过对海量金融领域专业基础语料的学习,针对研报、公告、舆情等数据,自动抽取有投研领域知识深度的问答对,丰富扩充投研信息数据库。
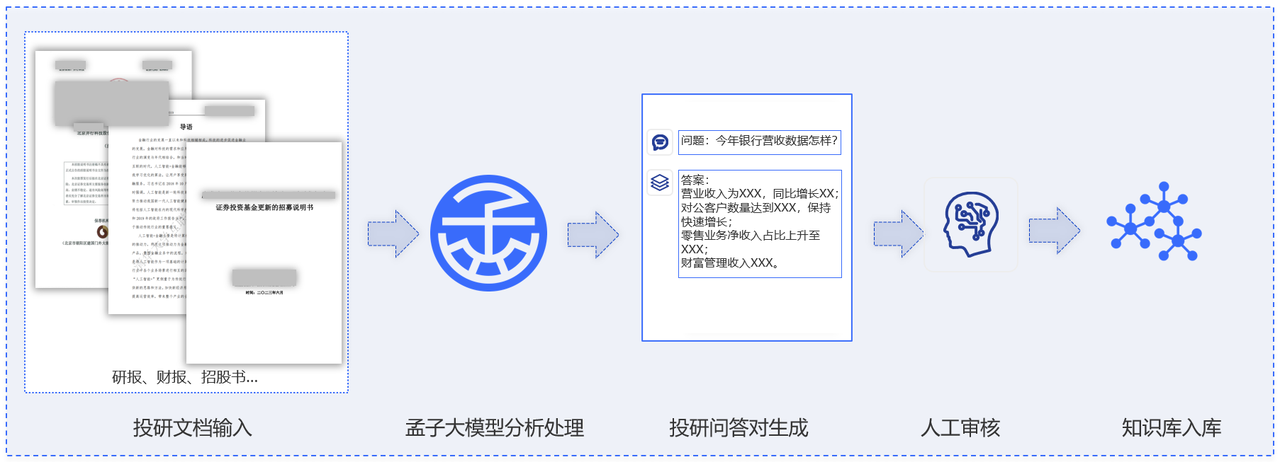
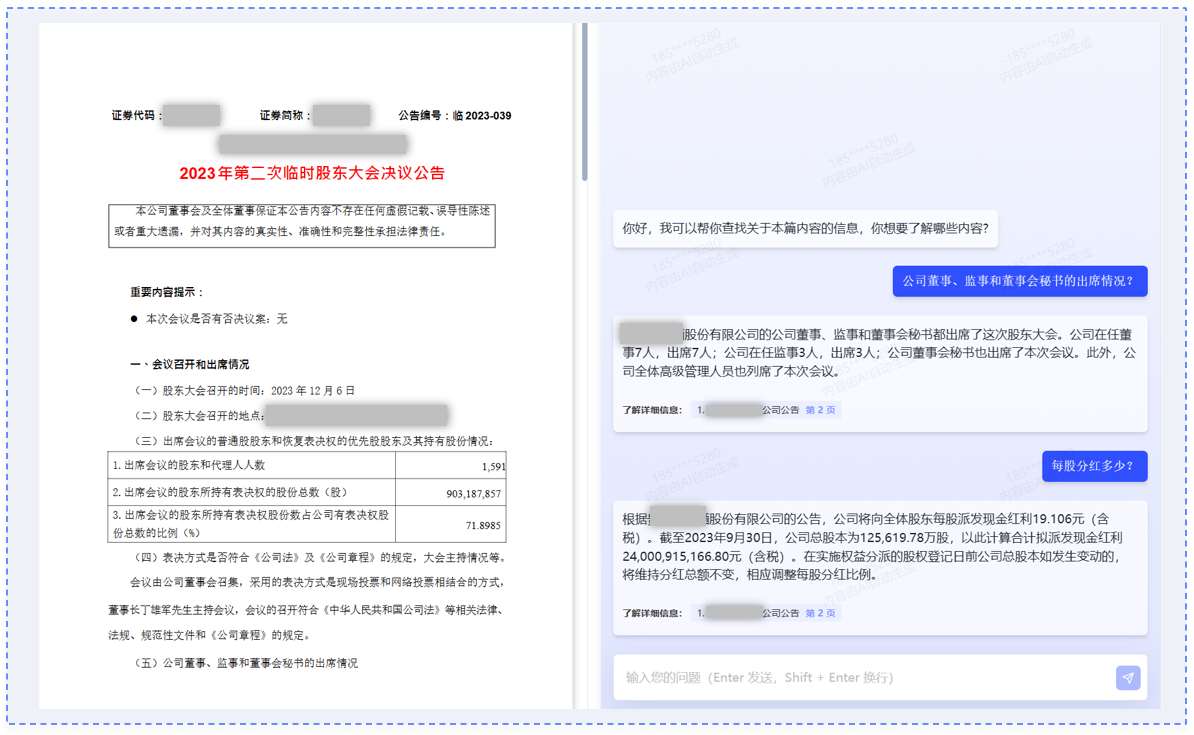
多数据源、多格式、多文档的智能问答
利用孟子大模型结合检索增强技术,通过强大的文本解析能力,搭建多文档聚合知识库;自研嵌入模型和基于预训练的排序模型,提升问答的准确性和真实性。
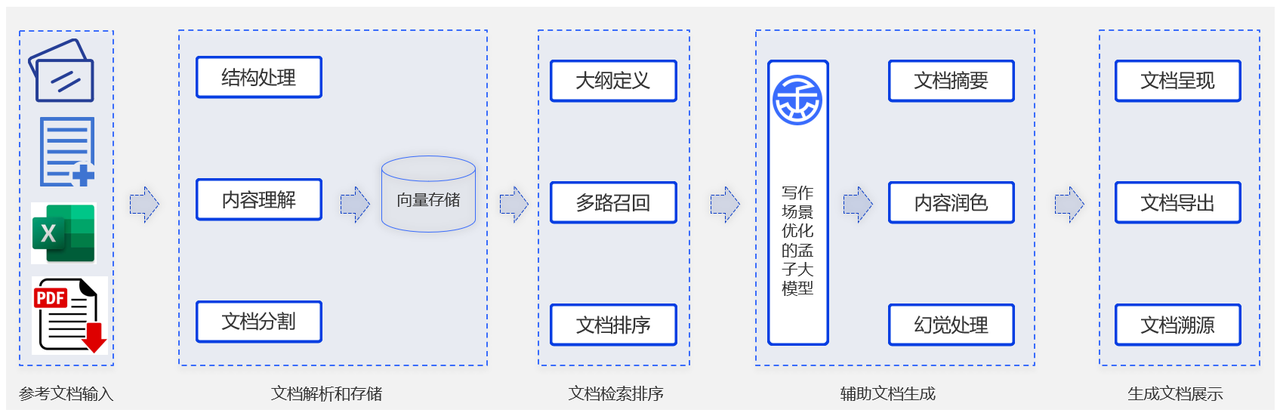
自定义模板的报告自动化生成
在财报、研报等金融垂直领域数据上进行训练,进一步加强孟子预训练模型的垂直领域写作能力。根据用户提供素材及自定义写作模板,减少幻觉,全面跟随写作要求,对齐写作规范。
业务价值

提升投研知识库的分析能力
通过投研业务关注问题、业务知识细化分析,逐步提升大模型的投研知识积累,自动生成有业务深度的问题,方便用户快速分析提问,获取投研知识。

提高知识获取的效率
针对封闭域文档,为投研分析师、研究员、产品经理等提供始终在线的投研分析助手,助力用户迅速把握文档要旨,实现快捷的知识摄取,提升工作效率。

优化报告呈现时间及内容
强化投研领域知识理解,沉淀报告标准化体系,快速检索、整合指定文档中碎片化信息,根据自定义报告模板,实现面向业务需求的内容快速生成和加工。
应用案例




