







欢迎来到澜舟孟子社区!
澜舟科技为有兴趣入门 NLP 技术的开发者提供各种学习资源指引
 扫码加入孟子开源社区微信群
扫码加入孟子开源社区微信群NLP 入门基础课程
NLP 高级课程
澜舟科技机器翻译技术分享
✎ 引言#
随着全球经济的进一步发展,国际贸易、跨国旅游及文化交流等活动越来越频繁,因此打通不同语言间交流壁垒的需求日益迫切。对此,澜舟科技基于自身在机器翻译技术的积累,建立了多语言、多领域的机器翻译引擎,于近日发布了英语和汉语金融互译引擎。 本文由澜舟科技研究员刘明童博士撰写,为大家带来澜舟科技的机器翻译技术分享。
01 机器翻译简介#
随着经济全球化的进展,不同语言间的翻译已经成为现代生活不可或缺的一部分。广义上讲,“翻译”是指把一个事物转化为另一个事物的过程。在人类语言的翻译中,一种语言文字通过人脑转化为另一种语言表达,这是一种自然语言的“翻译”。在现代人工智能系统中,机器翻译是指通过计算机将一种语言的文本自动翻译为另一种语言的文本,如将汉语翻译为英语,其中,汉语被称为源语言(Source Language),英语被称为目标语言(Target Language)。 整体来看,机器翻译经历了基于规则的方法、统计机器学习和神经网络机器翻译三个阶段。得益于过去多年技术的进步和语料库的累积,神经机器翻译技术为现代机器翻译带来了显著的质量提升,机器翻译在产业上取得了非常好的发展,在很多领域得到广泛应用,在一些语言间,机器翻译的性能可比肩专业译员。 神经机器翻译(Neural Machine Translation)是指直接采用神经网络以端到端方式进行翻译建模的机器翻译方法。神经机器翻译简化了统计机器翻译的中间步骤,采用一种简单直观的方法完成翻译工作:首先使用一个称为编码器(Encoder)的神经网络将源语言文本编码为一个稠密向量,然后使用一个称为解码器(Decoder)的神经网络从该向量中解码出目标语言文本,该模型通常称之为“编码器-解码器”(Encoder-Decoder)框架。近年来,以 LSTM 和 Transformer 为代表的神经机器翻译框架在性能上取得了显著提升,已被广泛应用在工业翻译平台。
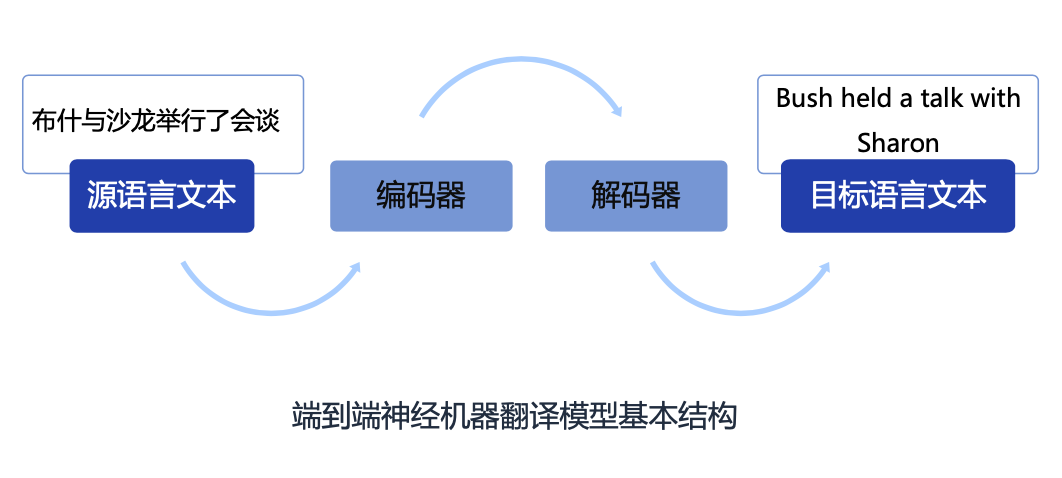
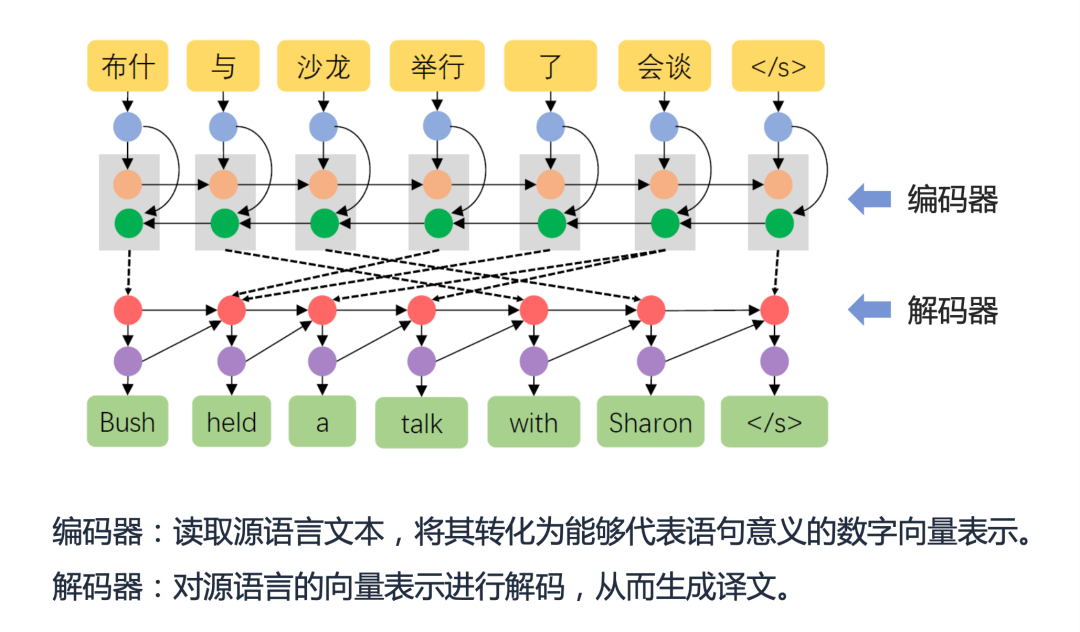
02 神经机器翻译训练方法#
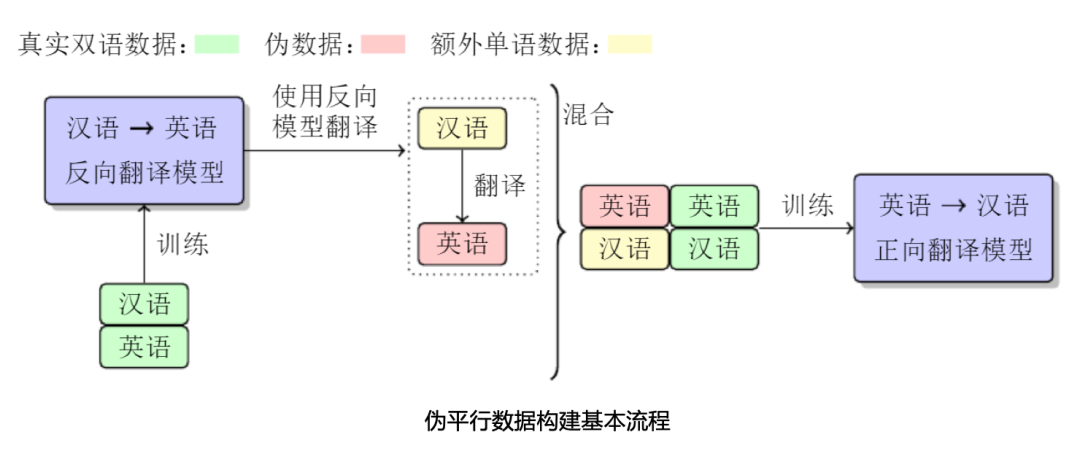
在现代人工智能系统中,核心算法+高质量数据是打造一个好的AI系统的双翼。构建一个高质量翻译模型,需要大量高质量双语平行句对,而人工构建这样的双语翻译数据,耗时耗力,短期很难实现。一个有效的方法就是利用单语数据增强翻译性能,常用的就是反向翻译技术(Back-Translation)。 反向翻译技术中利用单语数据的方法可归纳如下:为了改进英汉翻译模型,我们先用汉英平行数据训练一个反向翻译模型(汉语翻译为英语),然后将大规模汉语单语数据翻译为英语,从而构建出伪英汉平行语料,用来训练英汉翻译模型。最终,我们把标准的翻译数据和生成的伪数据混合在一起训练英汉翻译模型。
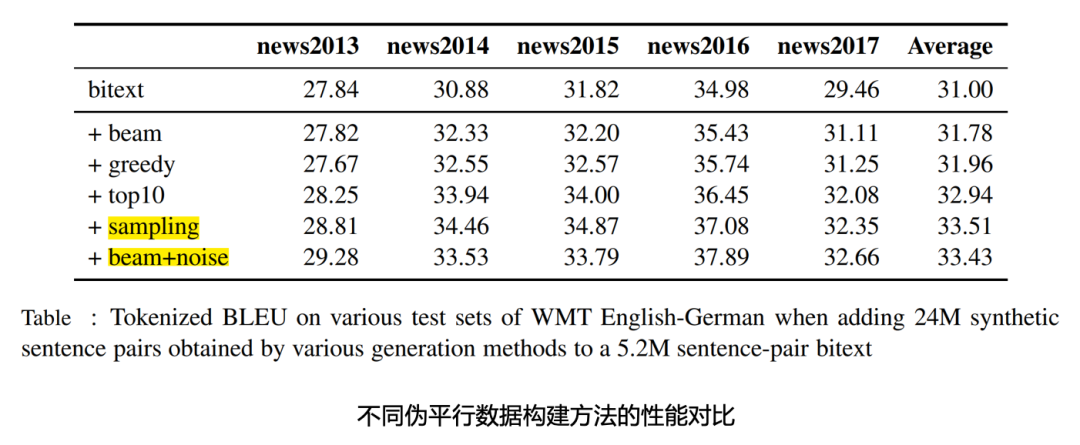
自然语言处理的难点之一就是语言表达的多样性。在机器翻译中,增大训练数据的多样性也是改进翻译模型性能的一个有效手段。相比于 Beam 和 Greedy 搜索算法,利用 Sampling 和 Beam+noise 方法生成伪平行数据,通过增加训练数据的多样性,可以进一步改进模型性能。
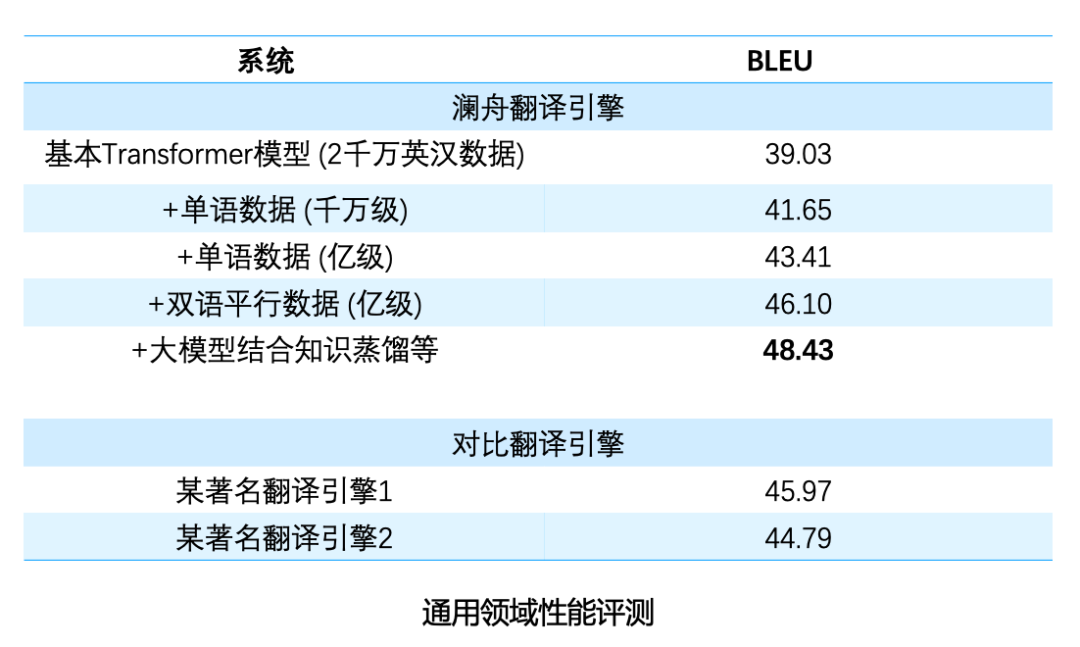
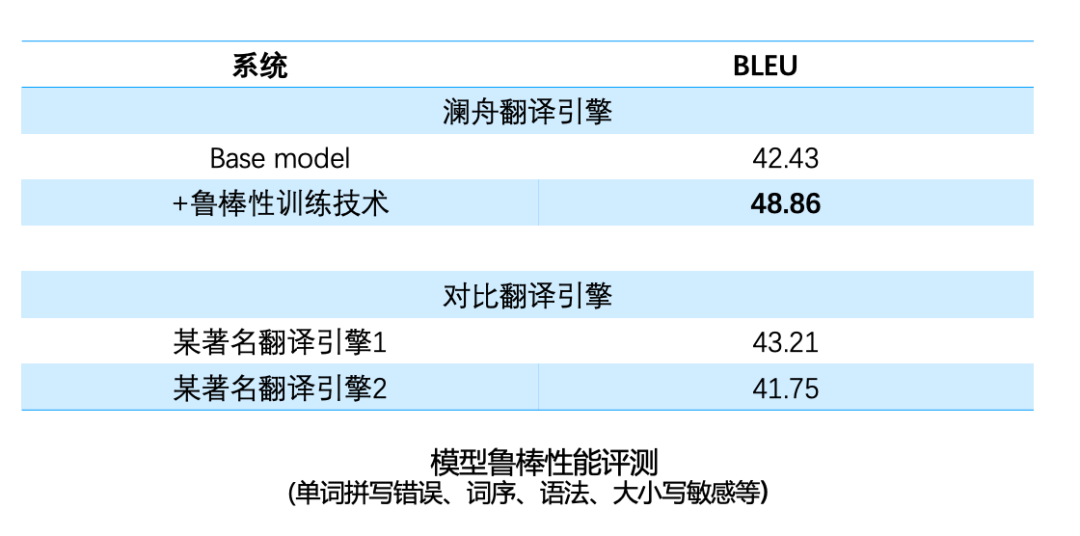
对比不同训练数据和策略下的模型性能,从上表可以看出,通过利用大规模双语数据和单语数据的结合,可以有效改进翻译性能。 通常在数据量比较充足的情况下,训练参数较多的神经网络模型(更宽、更深),能取得更好的性能。然而大模型推理速度较慢,不利于在线部署。对此的解决方法是,我们先训练一个大模型,然后采用知识蒸馏的方法利用大模型训练较小模型。通过训练较大模型提高性能,通过较小模型方便部署。 另一个在机器翻译中的关键问题是模型鲁棒性,比如在英文输入中,会出现单词拼写错误,词序、语法不正确的现象,还有一些场景,像浏览器翻译中会出现网页地址、邮箱、表情符号和一些噪声文本等,对此澜舟也针对性地做了一些优化。经过优化后,模型鲁棒性有明显的改善,可以更好应用在不同的场景中。
03 垂直领域机器翻译性能改进方法#
随着翻译技术的改进,以及人们对高质量翻译引擎的需求,通用引擎难以满足性能需要,如很多领域的专业术语翻译、特定表达等,实现这些翻译需求通常要做更细致的处理。对此,澜舟针对垂直领域翻译引擎做了很多优化工作,包括快速领域适应技术、半监督训练技术,及术语识别翻译等技术。 在自然语言处理中,一个词的语义通常与其所在的上下文或者领域相关。例如:“jacks”这个词语在工程机械领域中,应该是“千斤顶”的意思,但它还有“插座,杰克” 等别的意思,如何实现特定领域中专业术语的精准翻译,提高翻译体验,在垂直领域翻译引擎中十分重要。 一个简单有效的技术是引入术语翻译模块,术语翻译通过提供一个术语词典作为先验知识,从而实现精准翻译。在使用中,比如译员在翻译中,可以指定某个词只翻译为他想要的特定意思。实现术语翻译的两种典型方法是:基于槽替换的方法和基于术语注入的方法。基于槽替换的方法,在句子进入翻译模型之前将句子中的术语替换为变量槽,在模型翻译之后再将术语的翻译填回到对应的槽中,从而得到最终译文。基于术语注入的方法通过训练模型选择术语对应的翻译。

在金融领域,对比澜舟金融翻译引擎和已有两个著名引擎的结果,可以看到,通过对金融领域进行特定优化之后,澜舟金融翻译引擎在金融术语翻译上更准确。
英汉翻译:


汉英翻译:


04 澜舟机器翻译平台#
澜舟建立了机器翻译平台,通过大规模基础数据,训练多语言翻译模型,在此基础上,通过垂直领域的数据和技术,建立了各个垂直领域的翻译引擎。
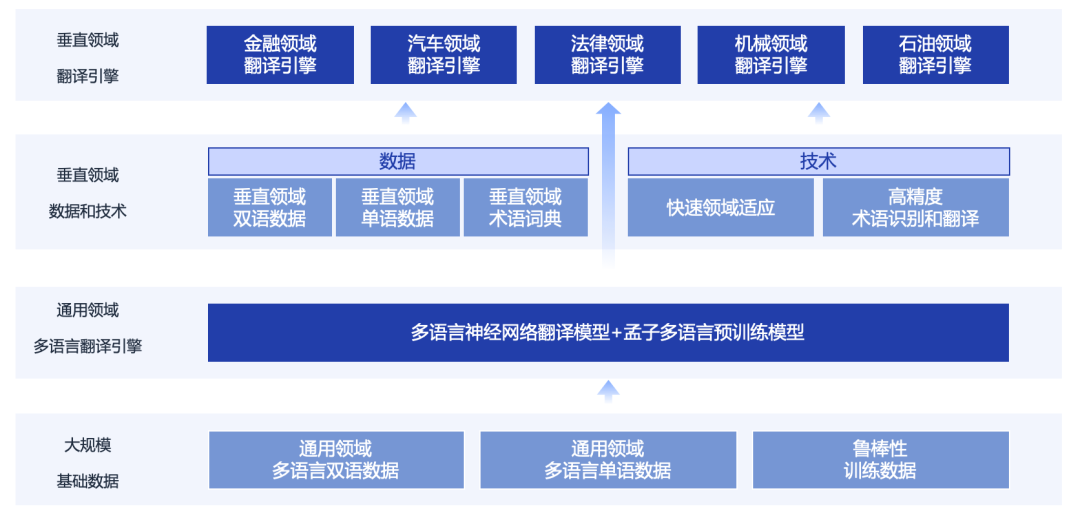
目前澜舟科技与传神语联网合作,已建立了通用翻译和多个领域的翻译引擎,包括机械、汽车、工程、法律、石油、合同、电力等众多领域,达到了世界领先水平。
05 机器翻译未来工作展望#
澜舟科技机器翻译研究取得了振奋人心的成果,在此基础上,未来仍有很多工作方向可以展望。
1)资源稀缺语言翻译:现有技术依赖大量双语平行语料,而为了提升资源稀缺语言对的翻译质量(如印尼语-汉语),需要研究多语言预训练模型或者其他技术。 2)改进行业翻译:由于不同行业表达风格的不同,在通用模型基础上为了满足专业需求,需要针对每个行业丰富语料库,同时识别术语和翻译术语。 3)训练和运行成本:模型训练需要高性能计算资源,而为了支持小设备上运行(如移动终端),需要进行模型压缩。 4)跨句级翻译:目前翻译是逐句进行的,为了保持翻译的前后连贯,仍需提升指代消解、性、数、格一致性等能力,解决跨级建模问题。
未来澜舟基于自身科技优势,将逐步建立多语言翻译引擎,也期待着在学术界和产业界的共同合作与努力下,未来机器翻译能取得更大的突破。 澜舟将始终坚持技术创新,推动人工智能领域的技术进步和落地,为产业升级、社会经济高质量发展、国家繁荣昌盛做出更大贡献。
参考文献:#
[1] 肖桐,朱靖波,《机器翻译:基础与模型》, 电子工业出版社, 2021. [2] Bahdanau D, Cho K H, Bengio Y. Neural machine translation by jointly learning to align and translate[C]. ICLR 2015. [3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008. [4] Edunov S, Ott M, Auli M, et al. Understanding Back-Translation at Scale[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 489-500. [5] Wu L, Wang Y, Xia Y, et al. Exploiting monolingual data at scale for neural machine translation[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 4207-4216. [6] Dinu G, Mathur P, Federico M, et al. Training Neural Machine Translation to Apply Terminology Constraints[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3063-3068. [7] Song K, Zhang Y, Yu H, et al. Code-Switching for Enhancing NMT with Pre-Specified Translation[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 449-459. [8] Liu Y, Gu J, Goyal N, et al. Multilingual Denoising Pre-training for Neural Machine Translation[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 726-742. [9] Xue L, Constant N, Roberts A, et al. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 483-498.




