







欢迎来到澜舟孟子社区!
澜舟科技为有兴趣入门 NLP 技术的开发者提供各种学习资源指引
 扫码加入孟子开源社区微信群
扫码加入孟子开源社区微信群NLP 入门基础课程
NLP 高级课程
论文领读 | 别再第四范式:看看新热点检索增强怎么做文本生成!
2021 年底,DeepMind 发布了检索型语言模型 Retro(点击绿字查看往期推送),引起了大家的广泛兴趣。显然,NLP Community 在 Prompt、对比学习等之后,找到了新的前(rè)沿(diǎn)方向。
检索增强文本生成主要有两个特点:
- 非参数方法:知识显式地以一种即插即用 (plug-and-play)的方式从模型外部获取,而不是保存在模型参数中。
- 简化文本生成问题:比起 from scratch 的文本生成,一些检索结果的指导可以降低文本生成的难度。
还是那句老话:「知识无涯,而模型之大有涯,以有涯随无涯,殆已!」 用轻量化模型结合检索,做成 Open System,是 NLP 发展的必然趋势!
论文标题
A Survey on Retrieval-Augmented Text Generation
作者机构
Huayang Li,Yixuan Su,Deng Cai,Yan Wang,Lemao Liu
论文单位
Nara Institute of Science and Technology, University of Cambridge, The Chinese University of Hong Kong, Tencent AI Lab
论文链接
https://arxiv.org/abs/2202.01110
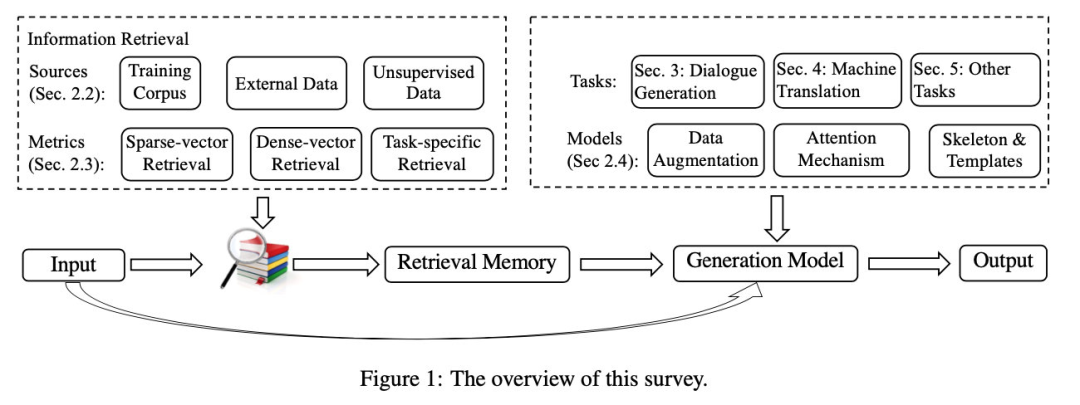
Retrieval-Augmented Paradigm#
形式化:
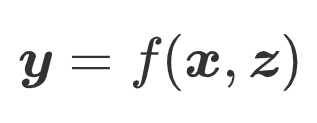
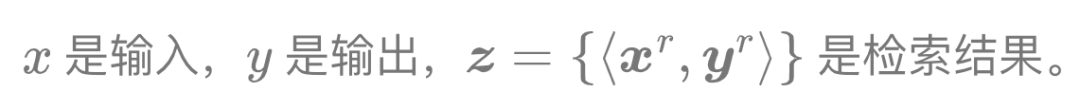
Retrieval Sources#
- 训练集:模型在 inference 阶段可以复用训练集数据
- 外部数据集:在训练集的基础上附加了一些信息,对于领域适应(domain adaptation)或者知识更新(knowledge update)非常适用
- 无监督数据:前两种都是有监督数据,这个 source 是的情况
Retrieval Metrics#
-
sparse-vector retrieval: 例如 TF-IDF、BM25等,主要是 relevance matching.
-
dense-vector retrieval: dual/cross-encoder等,主要是 semantic matching.
-
task-specific retrieval: 前两种方法是独立于 end-task 的,但实际上,仅仅靠和的相似度去断定的参考价值是不足够的,因此可以考虑统一 retrieval 和 end-task,训练一个 task-dependent retriever.
Integration#
有了检索结果,怎么用来增强语言模型呢?
- 数据增强:concatenating spans from with the original input
- 注意力机制:使用额外的 encoder 编码检索结果并通过 attention 将其融合到一起
- skeleton extraction : 从检索结果中抽取 skeleton,然后在生成过程中融合这些 skeleton
Skeleton : 一个能表示大体意思的句子模板 (a part of a whole utterance with irrelevant content masked )
Application#1: Dialogue Response Generation#
对话系统分为两种:闲聊 (chit-chat) 以及 任务导向型 (task-oriented). 这里聚焦于 chit-chat:
一般而言,对话有两种技术路线:
- Retrieval-based : 检索 real-world 中的对话并返回简单处理结果
- Generation-based : 依据对话历史进行文本生成
-
Shallow Integration: 将检索到的 instances 与 dialogue history 通过 encoder 等融合到一起。
-
Deep Integration: 一般而言是先从检索结果中抽取 skeleton,然后使用 skeleton 增强输出的响应。
-
Knowledge-Enhanced Generation: 不一定只检索 conversation,这种方式使用外部知识(如知识库、知识图谱等)进行生成增强 (Knowledge-grounded dialogue response generation). 目前检索增强的对话系统有以下 Limitations:
-
只考虑 one retrieved response, 怎么扩展到 multiple ?
-
能否使用一些自定义的 retrieval metric?尤其是对于可控对话生成任务。
-
retrieval pool 能否从对话语料扩展到多领域、多模态等更多的语料?
Application#2:Machine Translation#
检索增强的机器翻译,一般指的是翻译记忆库 (translation memory, TM) 相关的技术。
Statistical Machine Translation#
SMT 主要包含三个部分:phrase table extraction, parameter tuning 以及 decoding. 翻译记忆库(TM)在各个部分都可以发挥作用。
- constrained decoding: 首先使用编辑距离识别和 中的 unmatched segments 分别记为和,然后通过词语对齐(word alignment)算法找到对应的中的 aligned unmatched segments ,最后使用的解码结果替换对应的
- phrase table aggregation: 从检索结果中提取翻译规则,增强 phrase table, 然后重新调整 SMT 模型的参数
- parameter tuning: 翻译一句话时,首先检索一些相似的 pairs, 使用这些检索结果和给定的开发集一起,重新调整模型参数。也就是说,对于每个输入,都要独立地调整一下模型参数。
目前检索增强的 SMT 仍然有一些 Limitations:
- 检索仅考虑相关相似度 (relevance matching), 在语义上的匹配 (semantic matching)能力较弱
- 检索结果中蕴含的知识没有得到充分的利用
- 因为 SMT 是一个 pipeline, 无法进行 retrieval metric 以及 SMT 模型的联合优化(即无法采用上述 task-specific retrieval 的方式)
Neural Machine Translation#
仅在 Inference 中使用检索数据:在推断过程中,基于对一些特定的 target words 给予奖励 (reward),如增加特定词汇生成的概率等。 sentence-level :根据句子级别的相似度判断奖励的多少。例如与越相似,则中的某些词的采样概率就越高。 token-level : 根据 token 级别的相似度判断奖励的大小。例如与 越相似, 的采样概率就越高。
在训练阶段即可使用检索数据:
-
数据增强
-
使用门控、注意力、编码器等将整合到模型当中 目前检索增强的 NMT 也有一些 Limitations :
-
如何更好地确定 reward scores?
-
如何判断什么时候需要使用检索数据什么时候不需要?
其 他 任 务#
语言模型#
-
KNN-LM [1] : 以输入的 hidden representation 为 query, 从训练集中找到 k 个近邻样本,用这 k 个样本的 targets 通过插值改变直接 inference 的结果。
-
REALM [2] : 在预训练和精调阶段都有检索增强。分为 Knowledge-Retriever 和 Knowledge-Augmented Encoder. 前者负责基于输入检索 增强实例,后者负责基于输入和检索结果预测输出 (一般使用特殊符号将两者前后拼接起来过编码器就好了)
-
RAG [3] : REALM 是基于 MLM 的,而 RAG 基于 BART,新增了一个 Generator,把检索增强语言模型能做的任务范围扩充到了生成任务。
-
RETRO [4] : DeepMind 的检索增强语言模型,请看澜舟科技往期带读论文推送~
摘要、重述、风格迁移等#
可以是检索一些相似句进行增强,也可以检索一些 exemplar (比如 syntax template 等)。
Data-to-Text#
通过输入从海量无标签语料中检索一些 candidates,然后基于相似度等提取一些 fine-grained prototypes, 然后进行条件文本生成。
未 来 方 向#
-
Retrieval Sensitivity: 检索增强文本生成的一个瓶颈在于,高度依赖 query 与 retrieved instances 之间的相似性。一般来说,retrieval pool 越大,越容易找到更相似的样本,这个问题会越缓和。
-
Retrieval Efficeincy:因为新增了检索步骤,inference 会变得比较慢。因此需要减小 retrieval pool 的 size, 找到 sensitivity 和 efficiency 之间的平衡。
-
Local vs. Global Optimization:对于生成任务的 retrieval metric,training 和 inference 之间有一个 gap, 训练时只使用一部分检索到的数据进行局部优化,而在推理阶段需要对 retrieval pool 进行 global search. 因此需要研究更好的 retrieval metric.
-
多模态
-
Diverse & Controllable Retrieval
写 在 最 后#
现在我们回忆一下 Prompt:当谈到文本生成,我们说 Prompt 主要在四种场景中受益:低资源、低算力、统一场景、可控性。总结起来就是,通过低能耗的方式,习得调用模型内部记忆的能力,而不是通过高能耗的方式,强行转变模型记忆让它从「通才」变成「专才」。
现在检索增强进入社区视野后,我们对大模型(或者说 LMaaS, 见 [6])有了新的思考:如果说 Prompt 本质上是一种 model memory 的 query (隐式地从模型参数中检索知识),检索增强本质是一种 world data 的 query(显式地从开放的外界中检索知识),那么,不就可以进一步模拟人类的语言生成过程了吗:
一般而言,人类的大脑非常节能,只会保存并记忆关键而常用的信息,然后去学习如何调取这些记忆。而对于不常见、不关键的信息,一般采用外部记忆单元(如书本、互联网等)的帮助。大模型也应当是这样的:如果从 model memory 中 prompt 不到想要的信息,就换用 retrieval-augmented,然后再使用检索到的结果或者检索增强后的生成结果更新 model memory,一直持续下去。当用户基数足够大、调用次数足够多时,model memory 会逐渐收敛到只保存常见关键信息的稳定状态。
「知之为知之,不知为不知,是知也!」 模型知道怎么办,就 prompt 出结果来,如果不知道,就诚实地查询并学习就好了~
当然,检索到的信息也可以作为 prompt 的一种,类似于 in-context learning. 相当于是使用外部知识激发内部记忆,「百度一下,你就知道」~
这样能够解决的痛点在于:实际上,pretraining 习得的有用信息(知识)非常稀疏,甚至绝大部分可能是无用信息(这可能也是预训练模型不能直接用来做某些 end-task 的原因吧...)。通过这种交互式收敛的过程,能够保证模型知识的密集性,提高模型参数的利用率!那么:在基于 Prompt 和检索增强的时代,我们终于可以改变预训练-精调的范式,换成 LMaaS 的稳定状态范式!相信这样的大模型才更加接近人脑,毕竟人类语言的诞生,不是从文字数据开始的,而是从 interaction (人际交往)开始的。 当然,这只是一个脑洞级的想法,实际发展方向是否如此还说不准。毕竟现在的检索增强只能说是半开放的,因为 「外界」往往局限于某个训练集、知识库等,然而全开放的方式(Browser-assisted, 如 WebGPT [5])加上上面的图景又要面临低速推理、系统集成度过高、收敛过慢等等难题。
最后,把目光从天上回到地上:在大模型横行的当下,检索增强对于算力较弱的企业或者实验室,无疑是一个需要重视的「出圈锦囊」。
参考文献:
[1]. kNN-LM : https://openreview.net/pdf?id=HklBjCEKvH
[2]. REALM : https://arxiv.org/abs/2002.08909
[3]. RAG : https://arxiv.org/abs/2005.11401
[4]. RETRO : https://mp.weixin.qq.com/s/oJvi8GNDdHtqjlm6TMubMA
[5]. WebGPT : https://arxiv.org/abs/2112.09332
[6]. Black-Box Tuning for Language-Model-as-a-Service: https://arxiv.org/abs/2201.03514




