周明博士受邀在杭州云栖大会主论坛分享《认知智能的创新趋势》
2021-10-19
2021年10月19日,杭州·云栖大会正式开幕。周明博士受邀出席上午的主论坛,分享了《认知智能的创新趋势》。
AI 正由感知智能快速向认知智能迈进,未来的十年孕育着巨大的认知智能发展和创新的机遇,让产学研一起努力,迎接这个伟大的时代。

人工智能从上世纪五十年代达特茅斯会议发展到今天,经历了多次起伏,围绕着基于知识还是基于数据两条线,先后发展出了基于知识的符号系统和基于数据的统计机器学习和神经网络方法。目前基于神经网络的深度学习方法,在大数据和大算力支持下,在感知智能方面,语音识别、人脸识别、物体分类已达到与人相仿的水平,推动了人工智能在安防、质检、医疗图像识别和无人驾驶等领域的落地。
当前,AI 正由感知智能快速向认知智能迈进。计算机正在从能说会看,到能思考、能回答问题、能决策快速推进。认知智能的核心是自然语言处理。其应用目前已经非常普遍。比如机器翻译、聊天机器人、搜索引擎、摘要和问答,知识图谱等等。计算机通过感知智能获得的是对世界的感知,而从感知智能到认知智能后,将使得计算机理解与认识世界并能够改变世界。认知智能提供了从数据获取和分类、到信息抽取和检索、到知识推理再到洞见发现的全方位的能力。会同感知智能,将对各行各业产生深远的影响。

认识到认知智能的发展趋势和产业前景,我们在创新工场孵化了澜舟科技公司,提出了孟子新一代认知服务引擎的计划,希望促进行业工作效率。我们研制了孟子轻量化预训练模型,获得了中文 NLP 技术 CLUE 评测的第一名。在预训练基础上,开发了新一代的机器翻译、文本生成和行业搜索引擎等技术,并与若干头部公司合作实现了技术落地。与此同时,我们也在积极研究新型的推理机制,希望提升小样本学习和常识运用的能力。最近我们的认知服务引擎荣获了 HICOOL 创新大赛一等奖。

孟子认知服务引擎如何形成可用的解决方案呢?我们训练大规模预训练模型,支持文本和多模态内容,并通过云提供服务。我们从开源起步,正在过渡到SaaS、订制和 App。我们希望尽快把技术融入用户实际场景中,尽快获得反馈,快速迭代。
现有的各类智能云,需要企业要有能力针对自己企业产品需求,挑选、调用、修改相关功能。这通常需要专业人员,而众多的企业并没有这个条件。现有的云服务使用起来也不直观。为了帮助用户解决最后一公里的需求,我们正在开发柔性 AI 智能云技术,希望以傻瓜型的方式,用户只需要拖拉拽相应的功能,所见即所得,就可以实现自己预想的功能。
这里的核心技术之一预训练模型利用自监督方式学习一个语言模型。在此基础上,针对每一个 NLP 任务,用有限的标注数据进行微调可达到不错的性能。甚至 GPT-3 展示了对某些任务不经过微调也有一定的水平。这种预训练+微调技术,可以一套技术解决不同语言和不同场景的 NLP 任务,有效地提升了开发效率。这也标志着 NLP 进入到工业化实施阶段。
当前在预训练模型领域较为关注的研究重点包括:如何训练超大规模的模型、提升训练的效率、把知识融入到预训练模型、以及在微调阶段如何提升小样本学习能力等等。
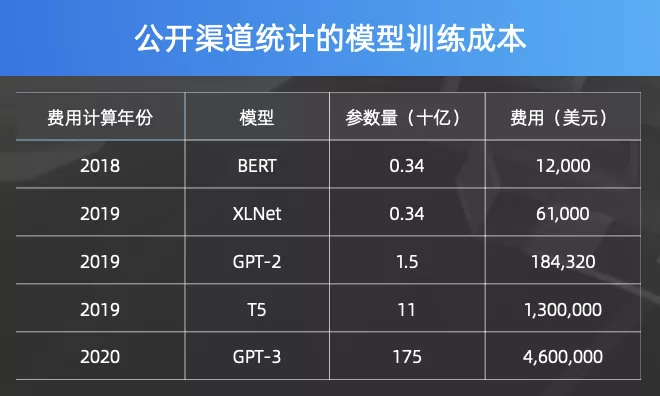
前面说过我们研制了孟子轻量化模型。为什么要研究轻量化模型呢?人们普遍认为,在相同网络架构和训练方法下,模型层次增加、模型参数增加,能力就一定增强。不过模型规模到了一定的程度之后,增强的幅度可能越来越小。在这个时候,也许不一定非要去盲目追求更大的模型,应把资源投入到如何提升模型能力。我们注意到训练一个大模型的代价很高,譬如 GPT-3 训练需要460万美金。大模型落地部署的代价也极大。随着摩尔定律逐渐枯竭,计算机硬件能力的增加速度赶不上模型参数的增加速度。统计表明至少差一个数量级。有鉴于此,我们重点研究轻量化的模型。
孟子轻量化预训练模型研究从训练优化、知识增强和数据增强三方面展开。训练优化上,在不改变模型结构、保证通用性的基础上,优化主流的自编码和自回归的训练方式,使得模型训练更快、性能更强、表现更鲁棒。知识方面,我们引入语言学知识和知识图谱来增强模型的上下文感知和认知推理能力。数据方面,我们使用领域数据,和其他语言的数据让模型可对垂直领域优化。因为是轻量化模型,所以模型训练、部署和维护的成本较低。针对新领域快速定制也容易实现。我们开源了3个孟子轻量化模型用于文本分析、生成、图片理解等应用。同时我们也开源了一个用于金融领域的预训练模型。
目前神经网络的方法依赖大规模的标注数据做端到端训练。这种黑箱式系统缺乏解释能力、也不具备常识推理能力。解决这个问题不是一件容易的事情,但是我们认为可以从如下两个方面推进:
第一、人脑在处理熟悉的事情的时候,依赖数据和直觉。比较快,缺乏解释性。这个能力通常被称作系统1的能力。而在遇到不很熟悉的时候,依赖规则、逻辑和推理,比较慢,但是具备可解释性。这个能力通常被称作系统2的能力。我们可以把前者类比于神经网络方法。后者类比于符号系统。为了改进目前的神经网络系统,图灵奖获得者 Benjio 认为深度学习应该从 system1 发展到 system2 的能力,system2 也还是深度学习模型,而不依赖符号系统。我认为不太容易。我觉得把这两个系统融合起来,也就是数据和知识融合起来寻找解决思路。

第二、现在的深度学习依赖数据做端对端的训练。这意味着针对一个新任务,要学习所有的能力。这就跟假定人脑做任何事情的时候都是从空白开始学习。实际上,人具备很多基础能力。这些基础能力针对一个新任务的时候,大部分的能力不动,只是小部分简单调整。我们设想模拟人脑,设计一系列基础能力和基础能力的微调机制。

基于基础能力的小样本学习求解复杂推理问题#
这是一个美国司法入学考试题目:有几个人 AB…F 要分到 XY 两个组。要满足几个约束条件:比如如果 A 在 X,则 B 要分在 Y。现在的问题是:如果 D、F 分到了一个组,下面的5个结论,哪一个结论是合理的?

电脑首先通过语义解析理解题目并形成逻辑表达式。在此基础上,进行推理获得答案。语义解析可以通过系统1方式实现,而推理可以通过系统2方式实现。逻辑表达式成为二者的连接。这里的语义解析和推理都是基础能力。他们分别可由若干更小的基础能力构成。他们串联起来并通过一组标注数据做微调。我们现在的系统可以进入到美国200所司法学院的90名左右的学校。未来还有很多问题尚待解决比如微调机制、常识引入等等。

认知智能正处在蓬勃发展的势头,取得了令人振奋的进步。我们正在搭建新一代认知服务引擎并希望通过柔性 AI 给企业赋能。但是,预训练模型的训练成本太高,效率低,推理能力差。由于数据的偏差,模型存在着隐私和伦理问题。我们希望未来的认知模型能够像人脑一样具备可解释性、小样本学习能力、具备常识。我们正在研究融合神经网络和知识系统的有效方法以及建立基础能力+微调的新机制。
我们坚信,通过产学研共同努力,未来十年,AI 的发展将从感知智能跨越到认知智能。认知智能必将全面提升企业效率并造福人类社会。





